[fs] ext4 disk layout
写在前面
这是2014年写的了,不过我搬到这里是在2021年4月11日,嗯,很长的时间跨度。这篇文章本来是在网易博客上的,后来网易博客关了,我就移到了CSDN,但损失了很多图片显示;所以,目前在网上也看不到完整的了,找到了当时写的DOCX文档,想就放这里看看。 不过,有的表述可能是错的;参考链接现在也已经找不到内容了。
Linux 文件系统简述
在Linux中对文件的组织方式与Windows的有一定的不同。在Windows下,可以看到磁盘的分区(如C:、D:等);而Linux中的文件系统中我们只能看到很多的文件夹与文件,系统把磁盘分区的信息在用户的层面上屏蔽掉了。展现出来的只有文件。 在Windows中,某一个文件系统在逻辑是从属于它所在的一个磁盘分区的。这种情况在Linux中恰恰相反,Linux中一切皆文件,这些文件被统一的组织为我们所看到的Linux文件系统,Linux的磁盘分区是从属于系统中的这个的文件系统的,并通过这个系统进行统一的管理。磁盘分区同样作为文件处理,被挂载到某一个文件夹下。Linux用一套统一的文件系统来呈现它所管理的所有资源,并把所有资源的管理层次抽象为文件系统的树状层次。
主流Linux默认使用文件系统格式:minix、ext、ext2、ext3、ext4 所谓的文件系统格式,就是指文件的数据在磁盘上的组织形式与存取机制。 这些文件系统格式都是基于inode的概念进行设计的。
硬盘结构
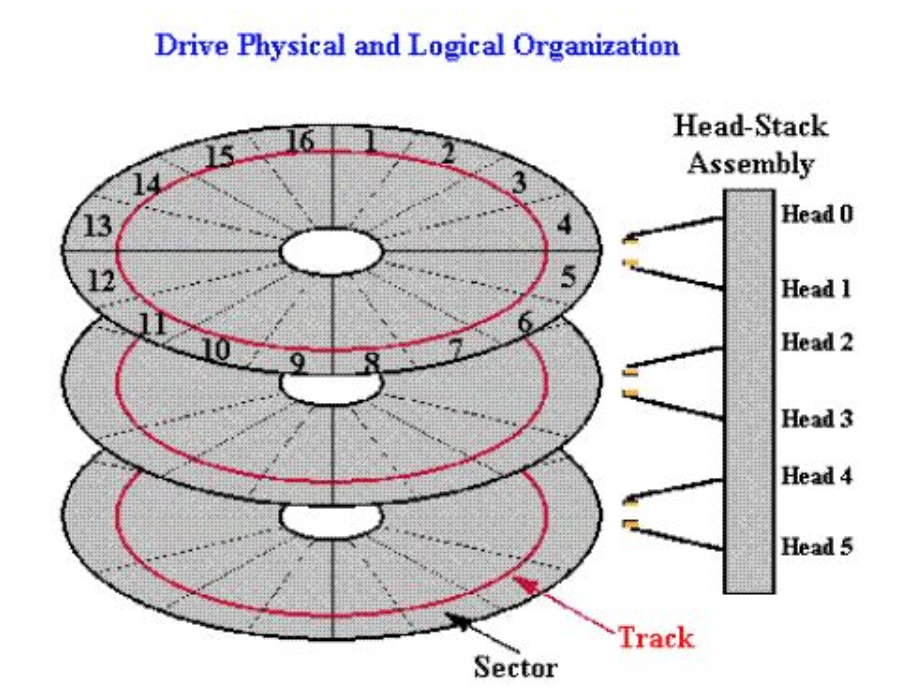
1.磁盘有多个盘片,每个盘片双面存储。 2.磁道(Track)磁头(Head)在盘片上画出的不同半径的同心圆。 3.柱面(Cylinder)全部盘片相同磁道组成的圆柱侧面。柱面是从0开始编号,由外向内。柱面越靠外,吞吐量越大。(因为越靠外转动的线速度越大) 4.扇区(Sector)盘片上的扇形区域。每个扇区512字节。是硬盘的基本单位。从1开始编号。每个扇区中的数据作为一个单元同时读出或写入。 5.硬盘的0柱面0磁头1扇区是系统启动时首先读取的扇区。
数据在读写时是按柱面Cylinder来进行的,即磁头Header读写数据时,首先在同一个柱面内从0磁头开始操作,依次向下在同一柱面的不同盘片(即是不同磁头)上进行操作,只有在同一柱面上所有磁头读写完后,磁头才会转移到下一柱面。 这是因为切换磁头是电子操作,切换柱面是机械操作。
系统启动扇区由三部分组成: 主引导记录(MBR) 硬盘分区表(DPT) 硬盘有效标记位(0x55AA)
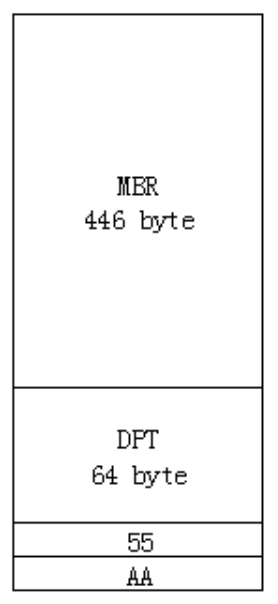
电脑上电后,开始执行主板的BIOS,完成一系列检测和配置后,如果是从硬盘启动,则将读入启动扇区。
MBR:master boot record(主引导记录)
DPT:disk partition table 共64字节,每16字节描述一个分区的属性。包括:引导指示符、起止H,S,C、系统ID、开始位置相对扇区数、分区总扇区数。
Linux文件系统管理策略
Linux的文件组织管理是以“物理块”为单位的,物理块的是块设备上大小相同的存储区域,其大小是在格式化文件系统时决定的。现在Linux的ext3/4文件系统默认块大小为4096byte。
Linux的ext2文件系统把一个分区中的块划分为多个块组,并且从0开始编号。每个块组包含等量的物理块(即块组都是一样大的,最后一个块组可能会小一些)。EXT系列的文件系统在磁盘组织上,都是使用“块”为最基础的单位来管理的。
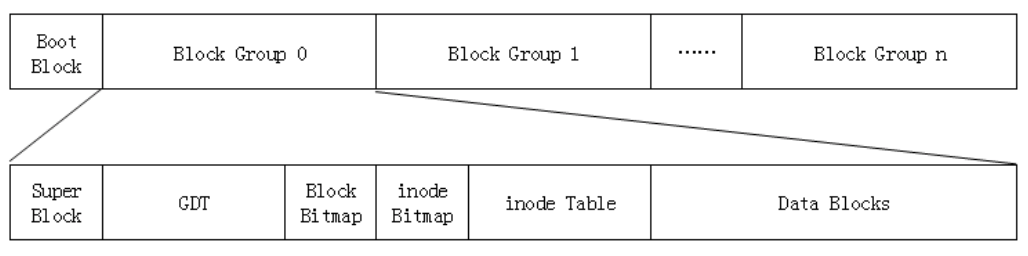
ext2文件系统
Linux的EXT系列文件系统,在升级的过程中,磁盘上数据组织方式的规则变化不是特别剧烈,所以不同的版本保持着兼容性。EXT2/3/4在组织上都是相似的,只是不断地在上一版本的基础上添加功能。
上图中的Boot Block(启动块)的大小是确定的1KB,启动块是由PC标准规定的,用来存储磁盘分区信息和启动信息。
任何文件系统都不能使用启动块。启动块之后才是ext2文件系统的开始。
EXT2文件系统块组的组成:
Super Block:超级块
GDT:块组描述符表
Block Bitmap:块位图
inode Bitmap:inode位图
inode Bitmap:inode表
Data Blocks:数据块
超级块 Super Block
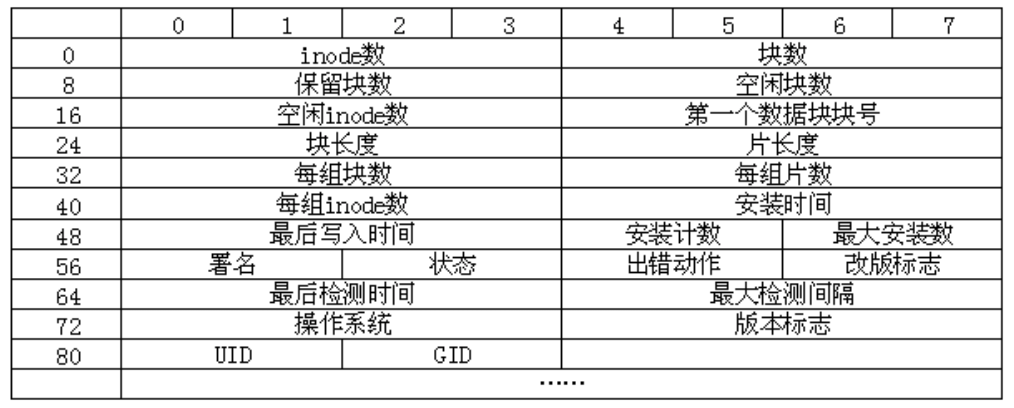
描述整个分区的文件系统的详细信息,例如块大小、文件系统版本号、上次挂载时间等。
超级块位于每个块组的最前面,每个块组包含超级块的内容都是一致的,也就是说它有很多的备份。
系统运行期间,把超级块复制到缓冲区内,只需把块组0的超级块读入内存,其它块组的超级块作为备份,在正常运行过程中并不被使用。
因为在每个块组中均存有超级块备份,一定程度上浪费了磁盘空间,所以引入了一个功能:如果相关的标示位被设置,超级块和块组描述符表只会被保存在第0、第3、5、7的整数幂块组;否则,冗余备份将出现在全部块组中。
块组描述符表 GDT
与超级块相似,GDT在每个块组的开头都有备份。块组描述符记录了各自对应的块组的详细信息,如该块组的块位图位置、inode位图位置等等,要想正常使用某一个块组,必须要正确读取此块组对应的块组描述符内容。
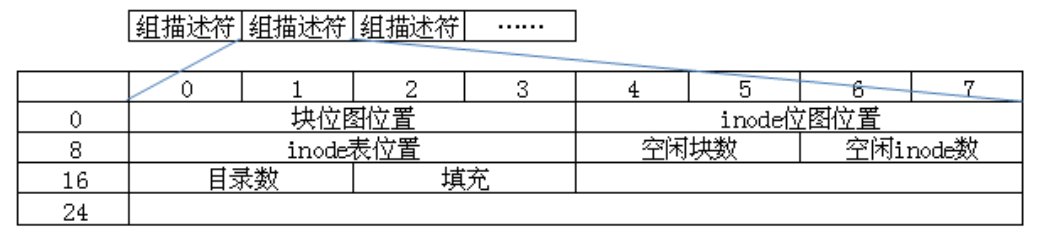
因为这些信息非常重要。一旦超级块损坏,就会丢失整个分区的数据;一旦组描述符损坏,就是丢失整个块的数据。
Ext2/3的一个块组描述符大小是32byte。
块位图,inode位图
位图的概念就是使用一个二进制位来代表某一个块或inode节点使用与否。数据块是用来保存文件数据,inode是用于记录某一个文件如何找到它所对应的数据块。
块位图与inode位图各占一个块(4096byte)。在位图的区域中,为1的位(bit)表示其对应的块或inode是已经使用的;为0表示空闲。
每一个块组均有自己的块位图与inode位图,用于记录本块组中块与inode的使用情况。一个块的大小为4K。则一个块位图所描述的块组最大为4096*8*4K=128MB
普通删除的机制:
普通的删除操作,不会去清空该文件的数据块内容,而只是释放该文件所占用的inode索引节点和数据块索引节点,即对inode位图和块位图中相关位清零,把它们标志为空闲状态。
如果能够找到文件对应的inode节点,由此查到相应的数据块,就可以从磁盘上恢复已删除的文件。
inode表,数据块
一个块组中的所有的inode组成了inode表,表项的序号就是inode号。
每个文件都有一个inode用于记录此文件的文件类型、权限、文件大小、时间信息等,以及保存数据的块的具体位置。
inode表占多少块在格式化是就要求决定,并写入块组描述符中,进行保存。 mke2fs的默认策略是:一个块组有多少个8KB就分配多少个inode。
至于一个分区中到底有多少个块组,取决于:“分区大小”和“块大小”。
分区中块组数 = 分区大小 / (块大小 * 8)
这是由于在每个块组中使用了一个数据块位图来标示数据块是否空闲,因此每个块组中最多可以有(块大小 * 8)个块;该值除分区大小就是分区中总的块组数。
inode节点的结构
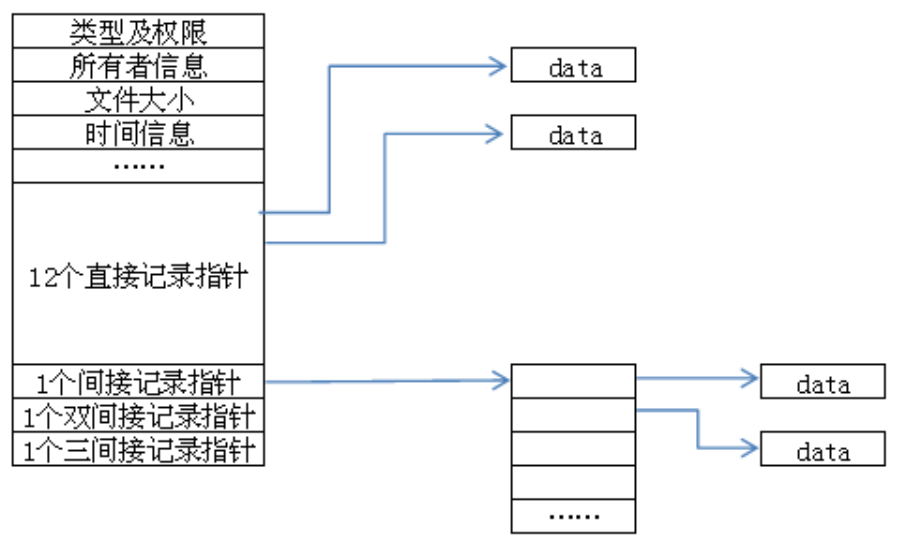
EXT2的基本构件是inode节点,是表示了文件系统树形结构的节点。每个文件由一个inode描述,且只能由一个inode描述。inode与文件一起存放在外存,系统运行时,把inode写入内存建立映像,加快文件系统速度。
对于常规文件,文件的数据存储在数据块中。
对于目录文件,该目录下是所有文件名和目录名存储在数据块中。
对于符号链接,如果目标路径名比较短,则直接保存在inode中;如果比较长,则分配一个数据块来保存。
对于设备文件、FIFO、socket文件,没有数据块,设备文件的主设备号和次设备号保存在inode中。
如果一个文件系统中保存着全都是很小的文件,那么inode被使用完时,可能很多数据块中的空间是没有使用的;如果一个文件系统中保存着全都是很大的文件,那么数据块被使用完时,可能还有很多inode节点没有被使用。
EXT2/3的inode大小固定为128byte,EXT4默认inode大小为256byte,多出来的空间可以用来记录其他扩展属性。
12个直接记录能够直接取得block号码,间接记录就是把它指向的block当做block号码的记录区,根据里面的记录再去找数据块,相当于二级指针;其他的同理。
EXT4的inode不是固定的,默认是256byte,inode的结构体是156byte,多出来的空间可被用来记录其他扩展的属性。在超级块中的相关项中记录了inode的大小。
创建、读取文件
在Linux下的ext2文件系统新建一个目录时,ext2会分配一个inode与至少一块block给该目录,inode记录该目录的相关权限与属性,并可记录分配到那一个block号码;而block则是记录在这个目录下的文件名与该文件占用的inode号码数据。
在Linux下的ext2文件系统新建一个文件时,ext2会分配一个inode与相对于该文件大小的block数量给该文件。
inode本身并不记录文件名,文件名的记录是在目录的block中。当我们要读取某个文件,就务必经过目录的inode与block,然后才能找到那个待读取文件的inode号码,最终才会读到正确的文件的block内的数据。
由于目录数是由根目录开始读取,因此系统通过挂载的信息可以找到挂载点的inode号码,此时就能够通过得到根目录的inode内容,并依据该inode读取根目录block内的文件名数据。再一层层地向下读取文件。
关于挂载点
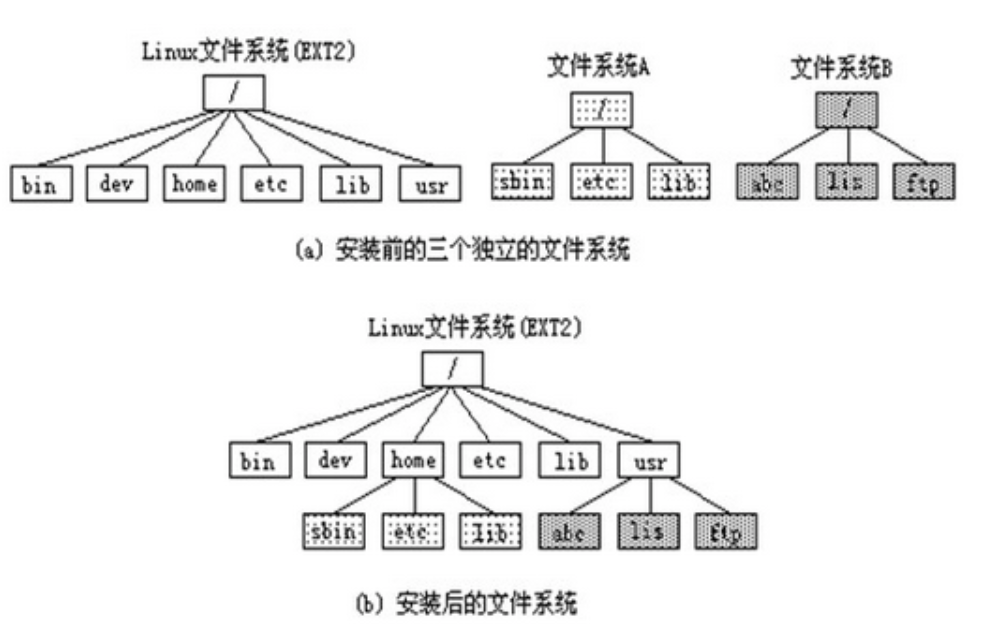
每个文件系统都有独立的Super Block,inode,block等信息,这个文件系统要能够连接到目录树才能够被使用。将文件系统与目录树结合的操作称之为挂载。挂载点一定是目录,该目录为进入该文件系统的入口,必须要“挂载”到目录树后,才能使用该文件系统。
日志文件系统
EXT2与EXT3格式完全相同,只是ext3分区最后一部分空间用来存放日志。
对文件系统进行的任何高级修改都会分为两步进行。首先,把待写块的一个副本存放在日志中;其次,当发往日志的IO数据传送完成时(即数据提交到日志),块就写入文件系统。当发往文件系统的IO数据传送终止时(即数据提交给文件系统),日志中的块副本就被丢弃。
简单来说,为了避免文件系统中的不一致性的情况发生,在文件系统当中规划出一个块,该块专门记录写入或修订文件时的步骤;也就是加入了日志文件系统。
所谓的不一致,即文件系统中的元数据记录的情况与实际磁盘使用的情况不相同。例如,inode已经分配,目录中还没记录这个文件,此时如果断电,已分配的inode将不能被找到也不能被收回。空间将得不到使用,除非重新格式化。
日志文件系统并不能保证数据不丢失(系统崩溃仍然可能造成数据丢失),它只能确保文件系统保持数据与元数据的一致的状态。另外,考虑到性能原因,日志文件系统通常不能把所有的块都拷贝到日志中,而只是拷贝元数据块(元数据包括超级块、块组描述符、索引节点块、间接寻址快、数据块位图、索引节点位图块)。
EXT4文件系统
Ext4是Ext3的进化版本,而后者是Linux操作系统以前最常用的文件系统。Ext4在很多方面对Ext3做了改善,这种改变要远多于Ext3对Ext2做的改变。Ext3和Ext2的差别只在日志系统,但是Ext4修改了文件系统的大部分重要数据结构,比如文件数据的存储方式。因此改变了设计,增强了性能,稳定性。同时,EXT3与EXT4相互兼容,即ext3文件系统可以以ext4的方式挂载,ext4文件系统也能以ext3的方式挂载,只不过此时不能使用ext4的新特性。
兼容Ext3文件系统
支持更大的文件系统(1EB)、更大的文件(16TB)
Extents
多块分配、延时分配
快速fsck
在线碎片整理等
但网上关于ext4的说明不是很多,现在只整理出这些:
Flexible Block Groups
弹性块组
这是ext4引入的一个特点。就是将连续的多个block groups绑在一起组成一个逻辑块组,称之为flex_group。
在一个flex_group中,第一个物理block group是存放当前flex_group全部的bitmap、inode表。也就是说将几个块组合并为一个更大的块组。比如flex_group的大小为4(就是由4个块组组成),其中的group0将按顺序存放Super Block、GDT、4个块组的块位图、4个块组的inode位图、4个块组的inode表,剩余的空间是用作数据块。就是说ext4将几个块组合并为一个更大的块组。
这是为了减少磁盘寻道操作,将频繁访问的块组资源放在连续空间上。同时也能一次申请更多的块;因为一次性申请的块最大数目是一个组的块数。
Meta Block Groups
元块组
一个块组最大128M,即2^27byte。Ext4块组描述符大小为64byte。则文件系统中最多有2^27 / 64 = 2^21个块组,则文件系统最大为256TB。
为解决256TB的限制,引入了META_BG的特点。Ext4文件系统中被划分为很多元块组,每个元块组由一簇块组组成,这些块组的组描述符被保存在一个单独的磁盘块中。(不再是保存整个磁盘的块组描述符)
Meta Block Groups特点将组描述符从这个文件系统拥挤的第一个块转移到了每个元块组中的第一个组。元块组中的块组里的块描述符,只描述了这个元块组中的块组,而不是整个文件系统的块组。这个特点将2^21个块组个数的限制提升到了硬件上的2^32个的限制,这将允许512PB的文件系统的大小。(2^32 * 128M = 512P)
EXT2/3的块组描述符都是32byte。EXT4在64bit的特点没有使能的情况下,块组描述符也是32byte。在64bit特点使能后,ext4的块组描述符是64byte。
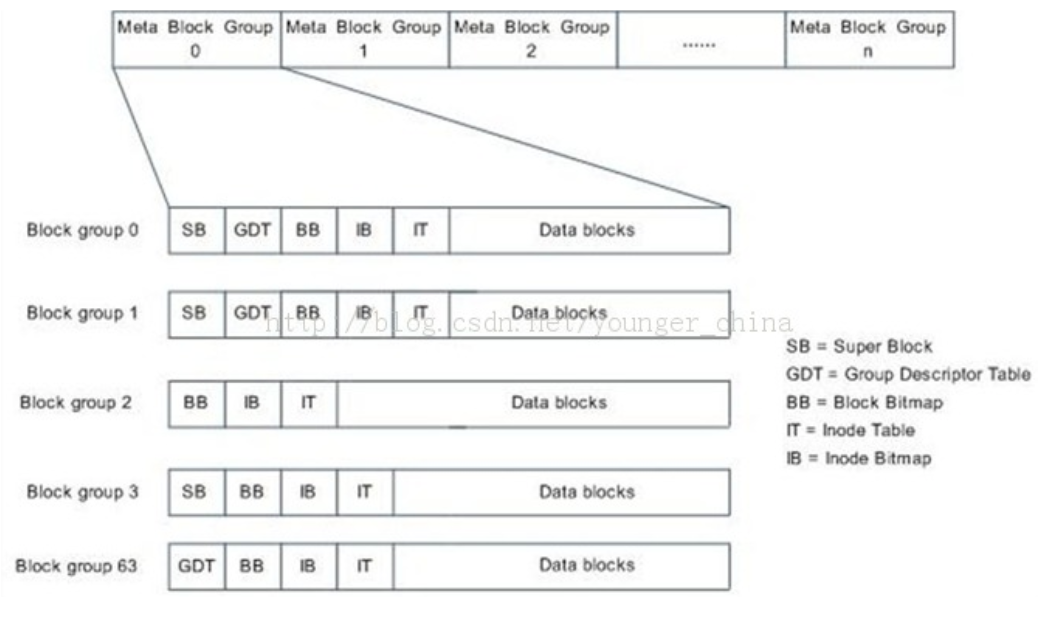
一个元块组包含了64个块组,每个块组大小是128M,所以一个元块组的大小可以到达(64 * 128M) = 8G。
Lazy Block Group Initialization
延迟组块初始化。
Ext4的新特征。目的是降低格式化的时间。
如果块组描述符的相关位被设置,对应块组中的inode位图和inode表将不被初始化。如果使能了块组描述符校验和,块组描述符也可以不初始化。
Special inode
0 不存在,ext4不存在inode0
- 存放损坏的数据块链表
- 根目录
- 用户配额的索引
- 组配额的索引
- Boot Loader
- 未删除的目录
- 预留的块组描述符表
- 日志的索引
- 为快照而排除的inode
- 副本inode,used for some non-upstream feature
- 第一个非预留的inode,通常用于lost+found目录
Block and Inode Allocation Policy
块与inode的分配策略
-
多块分配。当一个文件开始被创建时,块分配器会分配8K的空间,并假定这部分空间会马上写入。当这个文件关闭,没有使用的假定分配空间将释放。但如果假定正确,这个文件就会写入一个单独的multi-block extent。
-
延时分配。当写入的文件需要更多的块,文件系统会推迟决定在磁盘上的准确写入位置,直到所有被使用的缓冲区必须写入磁盘,才会进行写入磁盘操作。为了能够进行磁盘选址规划,除非必须要写入,ext4是尽量推迟的。
-
尽量使文件的数据与它的inode在同一个块组中。为了减少找到inode后去寻找文件内容的开销。
-
这个磁盘被分为多个128M的块组,为了维护数据的局部性。
Bigalloc
在格式化时指定单位大小为块数的2^N值。
可以支持更大单位的分配(不仅是以4K的块为单位进行分配),块组也不再是128M的大小,最小的分配单位变成“一簇”。块位图中所代表的也是“一簇”而不是一块。
如果文件系统中有很多小文件,并不合适用这种方法。
extent tree
Extent是ext4引入的一个新概念,专门用于管理大文件。一个extent是一个地址连续的数据块的集合。比如一个100MB的文件有可能只分配一个单独的extent,而不用像ext3那样新增25600个块记录。
在ext4中,文件的逻辑块映射已经被extent tree取代。在旧的方式下,一个连续1000个块的文件,需要一个间接块映射1000个记录;使用extents特性,映射减少到一个单独的结构体ext4_extent,其中ee_len=1000。如果flex_bg使能,那很可能分配一个大文件只使用单独一个extent。这样就能大大减少元数据块的使用,提高文件系统的性能。
在inode的结构体中extent flag被置位,才能使用这个特点。
Extents被组织成一个树。树的每一个节点以结构体ext4_extent_header开始。如果这个节点是一个内部节点,那这个header下面跟着结构体ext4_extent_idx的实例eh.eh_entries。这些index entries都分别指向各自的块,而这些块中包含看extent tree的更多的节点。
如果这个节点是一个叶子节点,那这个header下面跟着结构体ext4_extent的实例eh.eh_entries,这些实例则指向了文件的数据块。
根节点保存在inode.i_block中,且允许记录前4个extents而不使用额外的元数据块。
在结构体ext4_extent(叶子节点)中,记录了文件开始哪个块(ee_block)和这个extent的长度(ee_len)。对于ee_len,如果这个值<=32768,那么这个extent是已经初始化的。如果这个值>32768,则这个extent还没有被初始化,并且这个extent长度为(ee_len - 32768)。所以一个初始化了的extent长度最大32768。
Hash Tree Directories
如果inode中的EXT4_INDEX_FL被置位,目录会使用哈希树来组织与查找目录。为了向后兼容ext2,这个树实际上是隐藏在目录文件中的,伪装成“空”的目录数据块。之前的规定在线性的目录记录表的结尾被指向了inode0,旧的线性扫描算法会认为剩下的目录块是空白的,所以它就能接着正常工作下去。
EXT3/4支持的最大单个文件与最大文件系统
在网上看到的资料,对这两个上限值的描述并不统一,这里仅记录我的看法。 以下均以块大小为4KB讨论。
EXT3支持的最大单个文件
Ext3使用inode中的12个直接索引、1个间接索引、1个双间接索引、1个三间接索引去寻找含有此文件数据的块。则可以计算出单个文件大小为:
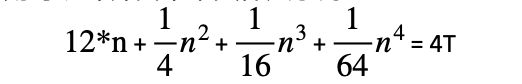
而实际ext3支持的单个最大文件时2T,这个是在代码中限定的最大值。
EXT3支持的最大文件系统
一个块组大小为128MB(2^27byte),一个块组描述符大小32byte。如果一个块组全部是组描述符(这个假设过于极限且不适用),(2^27)/32*128MB = 512TB。而实际上ext3最大文件系统最大为16TB,这个限制我并不是很清楚。
EXT4支持的最大单个文件
Ext4使用extent tree索引大文件。这个树的深度最大不能超过5层,以保证单个文件所占用的块数不超过2^32个(这似乎是硬件上的寻址限制)。
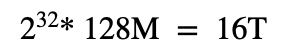
这就是ext4的单个文件的最大大小。
EXT4支持的最大文件系统
在上文中说到,最大的文件系统为2^32 * 128M = 512P,这是我翻译的Ext4 Disk Layout中的说法。而更多的人说ext4最大的文件系统是1EB,因为ext4的块寻址能够占用临近的空间,能够由32为扩展到48位,据说还为64位的寻址做好了准备。按这样说的话,ext4的最大文件系统为
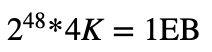
有不对的地方希望大家批评指正~
相关参考:
https://ext4.wiki.kernel.org/index.php/Ext4_Disk_Layout
http://blog.csdn.net/column/details/ext4-filesystem.html?page=1
等
2014-6-6